本文基于cocos2d-x v3.13。
cocos2d-x中,使用UI树来管理节点元素,在每帧的主循环中,都会遍历UI树,将每个节点的渲染命令发送给渲染器。
UI树 cocos2d-x中,UI树的根节点为场景scene,每一个节点都是Node的实例或其衍生类的实例,Node类提供了操作节点的各种API,可以方便地对节点增删改查。除此之外,Node中还包含了逻辑深度、坐标变换等信息。
UI树的遍历 在遍历UI树的过程中,主要完成两项工作内容,子节点排序和视图变换矩阵计算。
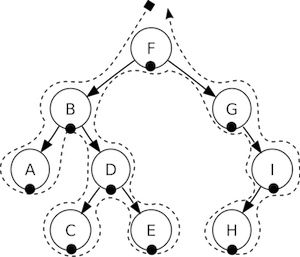
节点逻辑深度 对于每个节点,所有的子节点被分为两组,一组的localZOrder小于0,位于父节点的下部,先访问,另一组大于或等于0,位于父节点的上部,后访问。具体参见Node的visit()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 void Node::visit (Renderer* renderer, const Mat4 &parentTransform, uint32_t parentFlags) int i = 0 ; if (!_children.empty()) { sortAllChildren(); for ( ; i < _children.size (); i++ ) { auto node = _children.at(i); if (node && node->_localZOrder < 0 ) node->visit(renderer, _modelViewTransform, flags); else break ; } if (visibleByCamera) this ->draw(renderer, _modelViewTransform, flags); for (auto it=_children.cbegin()+i; it != _children.cend(); ++it) (*it)->visit(renderer, _modelViewTransform, flags); } else if (visibleByCamera) { this ->draw(renderer, _modelViewTransform, flags); } }
1 2 3 4 5 6 7 8 void Node::sortAllChildren () if (_reorderChildDirty) { sortNodes(_children); _reorderChildDirty = false ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 static void sortNodes (cocos2d::Vector<_T*>& nodes) #if CC_64BITS std ::sort(std ::begin (nodes), std ::end (nodes), [](_T* n1, _T* n2) { return (n1->_localZOrderAndArrival < n2->_localZOrderAndArrival); }); #else std ::stable_sort(std ::begin (nodes), std ::end (nodes), [](_T* n1, _T* n2) { return n1->_localZOrder < n2->_localZOrder; }); #endif }
上边代码中,在遍历子节点之前,父节点调用sortAllChildren()方法,实际上是将子节点按照逻辑深度localZOrder进行从小到大的排序,当子节点的逻辑深度localZOrder相等时,则按照子节点被加入到UI树中的顺序排序。调用各子节点visit()的顺序,决定着调用各节点draw()的顺序。
模型坐标变换 UI树遍历的过程中,还需要进行一些坐标变换。在开发过程中,程序员使用的是相对坐标或局部坐标,而最终OpenGL ES渲染绘制时需要使用世界坐标。cocos2d-x中,Node内部会维护一个视图变换矩阵,并将局部坐标参数和坐标变换矩阵传入OpenGL ES渲染管线,在渲染管线中完成局部坐标到世界坐标的转换。
1 2 3 4 5 6 7 8 9 10 void Node::visit (Renderer* renderer, const Mat4 &parentTransform, uint32_t parentFlags) uint32_t flags = processParentFlags(parentTransform, parentFlags); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 uint32_t Node::processParentFlags (const Mat4& parentTransform, uint32_t parentFlags) uint32_t flags = parentFlags; flags |= (_transformUpdated ? FLAGS_TRANSFORM_DIRTY : 0 ); if (flags & FLAGS_DIRTY_MASK) _modelViewTransform = this ->transform(parentTransform); _transformUpdated = false ; return flags; }
1 2 3 4 Mat4 Node::transform (const Mat4& parentTransform) return parentTransform * this ->getNodeToParentTransform(); }
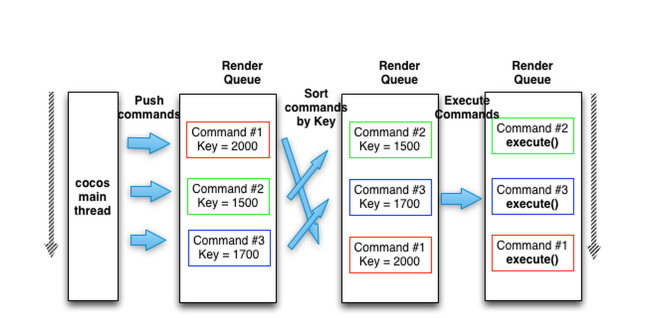
渲染系统 在cocos2d-x中,渲染系统的工作流程分为三个阶段:渲染命令的生成,渲染命令的排序,渲染命令的执行。如下图所示:
在详细解读工作流程之前,首先关注几个重要的概念。
重要概念 欲了解渲染系统的原理,必先了解一些重要的概念。
RenderCommand RenderCommand在draw的时候生成的一个渲染命令,并对渲染所需要的数据进行了封装。在实际使用过程中,RenderCommand分为很多种类,节点draw()的时候会完成一种特定种类RenderCommand的封装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 enum class Type { UNKNOWN_COMMAND, QUAD_COMMAND, CUSTOM_COMMAND, BATCH_COMMAND, GROUP_COMMAND, MESH_COMMAND, PRIMITIVE_COMMAND, TRIANGLES_COMMAND };
RenderQueue RenderQueue是用来存储 RenderCommand的类,RenderQueue内部维护了一个数组,数组中按不同分类存储了多个RenderCommand的vector,对外提供了加入、排序等方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class RenderQueue {public : enum QUEUE_GROUP { GLOBALZ_NEG = 0 , OPAQUE_3D = 1 , TRANSPARENT_3D = 2 , GLOBALZ_ZERO = 3 , GLOBALZ_POS = 4 , QUEUE_COUNT = 5 , }; public : void push_back (RenderCommand* command) void sort () RenderCommand* operator [](ssize_t index) const ; inline std ::vector <RenderCommand*>& getSubQueue (QUEUE_GROUP group) return _commands[group]; } protected : std ::vector <RenderCommand*> _commands[QUEUE_COUNT]; };
Renderer 渲染器Renderer是渲染工作的组织和调度者,内部维护了一个记录渲染命令组ID的栈,和一个RenderQueue的Vector:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class CC_DLL Renderer { public : void addCommand (RenderCommand* command) void addCommand (RenderCommand* command, int renderQueue) void pushGroup (int renderQueueID) void popGroup () int createRenderQueue () void render () protected : void processRenderCommand (RenderCommand* command) void visitRenderQueue (RenderQueue& queue ) std ::stack <int > _commandGroupStack; std ::vector <RenderQueue> _renderGroups; };
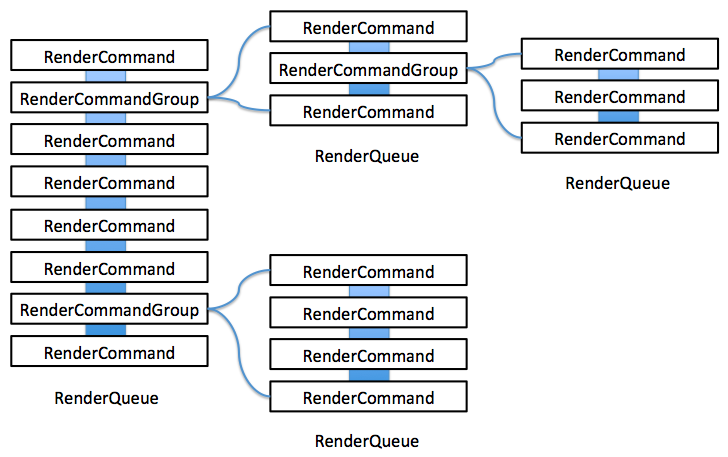
RenderCommandGroup 之前有说到过,是一种特殊的RenderCommand,并没有包含任何渲染的函数,指向的是一个RenderQueue。RenderQueue中又可以包含其他的RenderCommandGroup,即是RenderCommandGroup的嵌套。如下图所示:
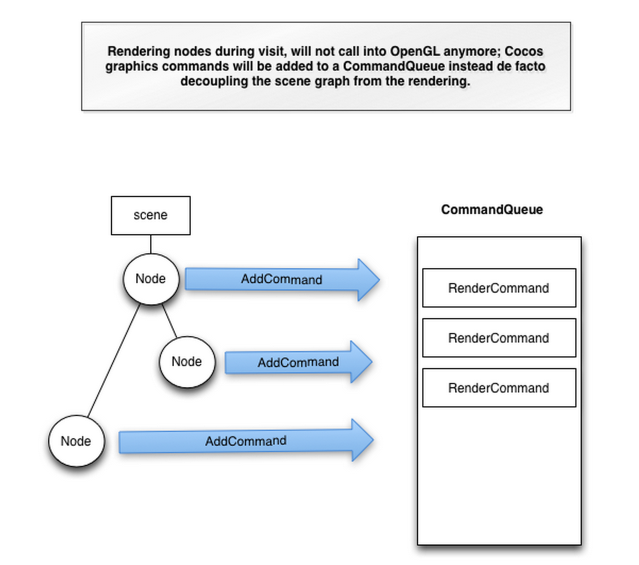
渲染命令的生成 遍历UI树各节点时,调用各节点的draw()方法,其作用通常是在方法中设置好相对应的RenderCommand参数,然后把此RenderCommand添加到CommandQueue中。
例如Sprite:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void Sprite::draw (Renderer *renderer, const Mat4 &transform, uint32_t flags) if (_texture == nullptr ) { return ; } { _trianglesCommand.init(_globalZOrder, _texture, getGLProgramState(), _blendFunc, _polyInfo.triangles, transform, flags); renderer->addCommand(&_trianglesCommand); } }
再例如DrawNode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void DrawNode::draw (Renderer *renderer, const Mat4 &transform, uint32_t flags) if (_bufferCount) { _customCommand.init(_globalZOrder, transform, flags); _customCommand.func = CC_CALLBACK_0(DrawNode::onDraw, this , transform, flags); renderer->addCommand(&_customCommand); } if (_bufferCountGLPoint) { _customCommandGLPoint.init(_globalZOrder, transform, flags); _customCommandGLPoint.func = CC_CALLBACK_0(DrawNode::onDrawGLPoint, this , transform, flags); renderer->addCommand(&_customCommandGLPoint); } if (_bufferCountGLLine) { _customCommandGLLine.init(_globalZOrder, transform, flags); _customCommandGLLine.func = CC_CALLBACK_0(DrawNode::onDrawGLLine, this , transform, flags); renderer->addCommand(&_customCommandGLLine); } }
都会用到Renderer::addCommand(RenderCommand* command),向Renderer中添加RenderCommand,遍历UI树和添加渲染命令的过程可以参考下图所示:
注意此处的addCommand有一个重载函数,增加RenderCommand的过程实际上需要先获取Renderer中_commandGroupStack顶部的RenderCommandGroup的ID,将RenderCommand添加到此RenderCommandGroup对应的RenderQueue里。
1 2 3 4 5 6 7 8 9 10 11 12 void Renderer::addCommand (RenderCommand* command) int renderQueue =_commandGroupStack.top(); addCommand(command, renderQueue); } void Renderer::addCommand (RenderCommand* command, int renderQueue) _renderGroups[renderQueue].push_back(command); }
RenderQueue内部有多个Vector存储不同种类的RenderCommand,在pushback的时候会分别对待,不同类型的RenderCommand会放进不同类型的vector中。
Renderer的构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static const int DEFAULT_RENDER_QUEUE = 0 ;Renderer::Renderer() { _commandGroupStack.push(DEFAULT_RENDER_QUEUE); RenderQueue defaultRenderQueue; _renderGroups.push_back(defaultRenderQueue); }
在Renderer中,_commandGroupStack[0] 对应的是默认的RenderQueue,后边会看到渲染时直接从Renderer中去执行的只有_renderGroups[0],其他的都是RenderCommandGroup所指向的RenderQueue。每当RenderQueue中添加RenderCommandGroup时,都会对应有push和pop的操作,以保证RenderCommand准确插到RenderCommandGroup对应的RenderQueue里,例如ClippingNode的visit方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 void ClippingNode::visit (Renderer *renderer, const Mat4 &parentTransform, uint32_t parentFlags) _groupCommand.init(_globalZOrder); renderer->addCommand(&_groupCommand); renderer->pushGroup(_groupCommand.getRenderQueueID()); _beforeVisitCmd.init(_globalZOrder); _beforeVisitCmd.func = CC_CALLBACK_0(StencilStateManager::onBeforeVisit, _stencilStateManager); renderer->addCommand(&_beforeVisitCmd); _stencil->visit(renderer, _modelViewTransform, flags); _afterDrawStencilCmd.init(_globalZOrder); _afterDrawStencilCmd.func = CC_CALLBACK_0(StencilStateManager::onAfterDrawStencil, _stencilStateManager); renderer->addCommand(&_afterDrawStencilCmd); int i = 0 ; bool visibleByCamera = isVisitableByVisitingCamera(); _afterVisitCmd.init(_globalZOrder); _afterVisitCmd.func = CC_CALLBACK_0(StencilStateManager::onAfterVisit, _stencilStateManager); renderer->addCommand(&_afterVisitCmd); renderer->popGroup(); }
其中:
1 2 3 4 5 6 7 8 9 10 11 void Renderer::pushGroup (int renderQueueID) CCASSERT(!_isRendering, "Cannot change render queue while rendering" ); _commandGroupStack.push(renderQueueID); } void Renderer::popGroup () CCASSERT(!_isRendering, "Cannot change render queue while rendering" ); _commandGroupStack.pop(); }
渲染命令的排序 在每帧结束前调用Renderer的render方法,详见下面代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void Renderer::render () _isRendering = true ; if (_glViewAssigned) { for (auto &renderqueue : _renderGroups) { renderqueue.sort(); } visitRenderQueue(_renderGroups[0 ]); } clean(); _isRendering = false ; }
可以看到是先对RenderQueue内部的渲染命令进行排序,visitRenderQueue(_renderGroups[0]);,先看排序部分:
1 2 3 4 5 6 7 void RenderQueue::sort () std ::sort(std ::begin (_commands[QUEUE_GROUP::TRANSPARENT_3D]), std ::end (_commands[QUEUE_GROUP::TRANSPARENT_3D]), compare3DCommand); std ::sort(std ::begin (_commands[QUEUE_GROUP::GLOBALZ_NEG]), std ::end (_commands[QUEUE_GROUP::GLOBALZ_NEG]), compareRenderCommand); std ::sort(std ::begin (_commands[QUEUE_GROUP::GLOBALZ_POS]), std ::end (_commands[QUEUE_GROUP::GLOBALZ_POS]), compareRenderCommand); }
RenderQueue对不同的vector中的渲染命令按照规则进行排序,主要是针对TRANSPARENT_3D,GLOBALZ_NEG,GLOBALZ_POS三种,对于globalZOrder为0的vector不需要排序。
渲染命令的执行 在排序完成后,会调用visitRenderQueue(_renderGroups[0]);,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 void Renderer::visitRenderQueue (RenderQueue& queue ) queue .saveRenderState(); const auto & zNegQueue = queue .getSubQueue(RenderQueue::QUEUE_GROUP::GLOBALZ_NEG); if (zNegQueue.size () > 0 ) { for (auto it = zNegQueue.cbegin(); it != zNegQueue.cend(); ++it) { processRenderCommand(*it); } flush (); } const auto & opaqueQueue = queue .getSubQueue(RenderQueue::QUEUE_GROUP::OPAQUE_3D); if (opaqueQueue.size () > 0 ) { for (auto it = opaqueQueue.cbegin(); it != opaqueQueue.cend(); ++it) { processRenderCommand(*it); } flush (); } const auto & transQueue = queue .getSubQueue(RenderQueue::QUEUE_GROUP::TRANSPARENT_3D); if (transQueue.size () > 0 ) { for (auto it = transQueue.cbegin(); it != transQueue.cend(); ++it) { processRenderCommand(*it); } flush (); } const auto & zZeroQueue = queue .getSubQueue(RenderQueue::QUEUE_GROUP::GLOBALZ_ZERO); if (zZeroQueue.size () > 0 ) { for (auto it = zZeroQueue.cbegin(); it != zZeroQueue.cend(); ++it) { processRenderCommand(*it); } flush (); } const auto & zPosQueue = queue .getSubQueue(RenderQueue::QUEUE_GROUP::GLOBALZ_POS); if (zPosQueue.size () > 0 ) { for (auto it = zPosQueue.cbegin(); it != zPosQueue.cend(); ++it) { processRenderCommand(*it); } flush (); } queue .restoreRenderState(); }
基本上是依次执行各类不同的渲染命令,调用了Renderer::processRenderCommand(RenderCommand* command)方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 void Renderer::processRenderCommand (RenderCommand* command) auto commandType = command->getType(); if ( RenderCommand::Type::TRIANGLES_COMMAND == commandType) { flush3D(); auto cmd = static_cast <TrianglesCommand*>(command); if (_filledVertex + cmd->getVertexCount() > VBO_SIZE || _filledIndex + cmd->getIndexCount() > INDEX_VBO_SIZE) { drawBatchedTriangles(); } _queuedTriangleCommands.push_back(cmd); _filledIndex += cmd->getIndexCount(); _filledVertex += cmd->getVertexCount(); } else if (RenderCommand::Type::MESH_COMMAND == commandType) { flush2D(); auto cmd = static_cast <MeshCommand*>(command); if (cmd->isSkipBatching() || _lastBatchedMeshCommand == nullptr || _lastBatchedMeshCommand->getMaterialID() != cmd->getMaterialID()) { flush3D(); CCGL_DEBUG_INSERT_EVENT_MARKER("RENDERER_MESH_COMMAND" ); if (cmd->isSkipBatching()) { cmd->execute(); } else { cmd->preBatchDraw(); cmd->batchDraw(); _lastBatchedMeshCommand = cmd; } } else { CCGL_DEBUG_INSERT_EVENT_MARKER("RENDERER_MESH_COMMAND" ); cmd->batchDraw(); } } else if (RenderCommand::Type::GROUP_COMMAND == commandType) { flush (); int renderQueueID = ((GroupCommand*) command)->getRenderQueueID(); CCGL_DEBUG_PUSH_GROUP_MARKER("RENDERER_GROUP_COMMAND" ); visitRenderQueue(_renderGroups[renderQueueID]); CCGL_DEBUG_POP_GROUP_MARKER(); } else if (RenderCommand::Type::CUSTOM_COMMAND == commandType) { flush (); auto cmd = static_cast <CustomCommand*>(command); CCGL_DEBUG_INSERT_EVENT_MARKER("RENDERER_CUSTOM_COMMAND" ); cmd->execute(); } else if (RenderCommand::Type::BATCH_COMMAND == commandType) { flush (); auto cmd = static_cast <BatchCommand*>(command); CCGL_DEBUG_INSERT_EVENT_MARKER("RENDERER_BATCH_COMMAND" ); cmd->execute(); } else if (RenderCommand::Type::PRIMITIVE_COMMAND == commandType) { flush (); auto cmd = static_cast <PrimitiveCommand*>(command); CCGL_DEBUG_INSERT_EVENT_MARKER("RENDERER_PRIMITIVE_COMMAND" ); cmd->execute(); } else { CCLOGERROR("Unknown commands in renderQueue" ); } }
此处是根据RenderCommand的类型,选择不同的处理方式,直接或间接调用OpenGL的api,执行部分在诸如Renderer::drawBatchedTriangles(),MeshCommand::execute(),CustomCommand::execute()等中,而处理RenderCommandGroup时则需要去visit它指向的RenderQueue。
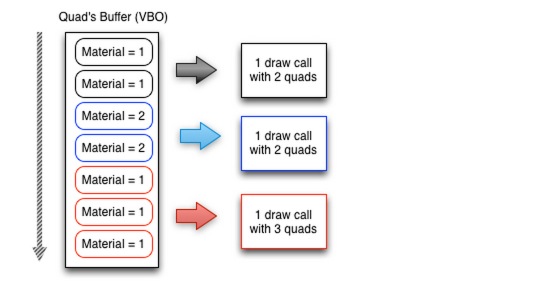
注意在处理TrianglesCommand时,渲染系统会有自动批处理机制,如下图所示:
渲染序列中相邻的材质Material相同(包括相同的textureID,相同的glProgramState,相同的BlendFunction)的TrianglesCommand会合并渲染,减少drawCall的数量。对于满足要求的TrianglesCommand,Renderer首先会将其插入到一个vector中:_queuedTriangleCommands.push_back(cmd),然后再整体批绘制drawBatchedTriangles()。
REFERENCE http://cocos2d-x.org/wiki/Introduction_to_New_Renderer http://cocos2d-x.org/docs/programmers-guide/basic_concepts/index.html 我所理解的cocos2d-x http://blog.csdn.net/bill_man/article/details/35839499 http://blog.csdn.net/cbbbc/article/details/39449945 cocos2d-x v3.13 source code