最近做了性能优化相关的工作,其中一些是关于战斗模块的渲染的。主要是对场景中使用的基于SkinnedMeshRenderer的网格进行了一些合批优化(降DC),记录如下。项目使用的Unity版本为5.6.4p1。
游戏中的战斗模块是这样的:
- 战斗逻辑由服务器承担,战斗瞬间完成,将战斗过程发给客户端,客户端负责播放;
- 场景中有敌我双方最多12个方阵(双方各2排3列),每个方阵由12个小兵组成(3排4列);
- 战斗基于回合制,敌我各个方阵依次攻击,攻击时会出列,冲到目标方阵前,攻击完成后返回;
- 小兵使用的是带动画的3D模型,使用AnimationController控制动作;
- 每个方阵的小兵是完全一致的(含模型、贴图、动作)
综上,使用战场管理器根据后端发来的战斗数据,改变各个方阵的position以及控制AnimationController来实现战斗过程的播放。
战斗模块中的渲染部分,从最初的版本到目前的一个可接受的版本,总共经历了多次迭代,以下详细记录,本文中使用的截图非项目截图(单个模型面数小于项目中使用的面数,此处使用的模型来自AssetStore,仅供演示使用)。本文的工程可以在github上看到所有源码。
原始版本
每个方阵12个小兵,实实在在地放了12个SkinnedMeshRenderer(后边简称为SMR),在方阵的脚本中保存了所有的AnimationController(后边简称AC),当方阵要移动时则移动所有的SMR,播放动画时同时为所有AC设置状态。
此方案每方阵共计12个SMR和12个AC。
两轮迭代
迭代一:共享网格
每个方阵放1个带SMR的小兵模型,每帧Bake网格,同时有12个MeshRenderer,其MeshFilter指向的Mesh即SMR每帧Bake出的Mesh。考虑到SMR的AC会控制SMR及父节点的运动,保留了所有的AC,仅仅把实际用来展示的SMR换成了普通的MeshRenderer。
此方案每方阵共计1个SMR和12(或13)个AC,节省了一些骨骼动画的计算。所有的MeshRenderer使用相同的网格和材质,但是由于单个模型顶点数的原因无法合批绘制。
迭代二:GPU Instancing
每个方阵1个带SMR的小兵模型,每帧需要Bake,并将Bake的Mesh使用Graphics.DrawMeshInstanced在指定的位置绘制12份。这一操作需要系统支持GPU Instancing并且材质(shader)也要支持。大概是在shader中增加以下的代码。
1 | #pragma multi_compile_instancing |
在顶点着色器的输入的结构体中增加:
1 | UNITY_VERTEX_INPUT_INSTANCE_ID |
在顶点着色器函数中增加:
1 | UNITY_SETUP_INSTANCE_ID(v); |
其中v是顶点着色器的输入。这里是本文中使用的支持Instancing的shader。
最后不要忘了将材质是否支持GPU Instancing属性设置为true。
此方案每方阵共计1个SMR和1个AC,但需要系统和材质支持GPU Instancing。12个小兵只需一个DrawCall即可绘制出来。当整个方阵移动时,需要手动更新这些Instancing的变换矩阵。
目前项目中使用了结合了迭代一和迭代二的方案,首先会根据系统和材质是否支持GPU Instancing做出判断,如果支持则使用迭代二的方案,否则使用迭代一的方案。
备选方案:GPU Instancing的共享网格
如果系统支持GPU Instancing且使用迭代二中支持GPU Instancing的材质,在使用迭代一共享网格方案时也可以合批(按照GPU Instancing处理,可以突破最大顶点数对合批的限制)。
与迭代二相比,这种备选方案不需要计算Instance绘制时的变换矩阵,但是却依赖AC来控制各小兵中SMR及其父级节点的变换。
方案汇总
在一台支持GPU Instancing的机器上对比四种方案如下:
| 方案A | 方案B | 方案C | 方案D |
|---|---|---|---|
| 原始版本 | 迭代一 | 迭代二 | 备选方案 |
以下依次是方案ABCD场景statistics:
方案A:
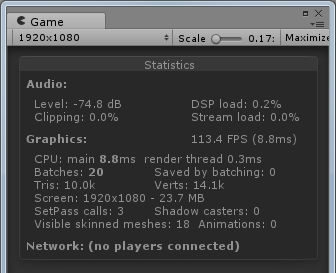
方案B:
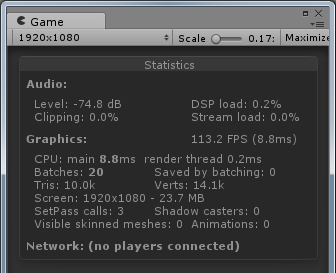
方案C:
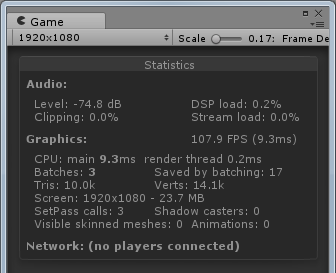
方案D:
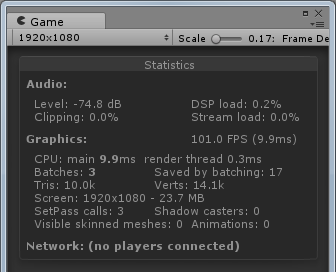
可以看到基本上方案A和方案B是同一个level的,方案C和方案D是同一个level,FPS由于一直波动所以截取到的数值只能表现出大概的趋势。
下边依次是方案ABCD绘制Frame截图(使用FrameDebugger截取):
方案A:
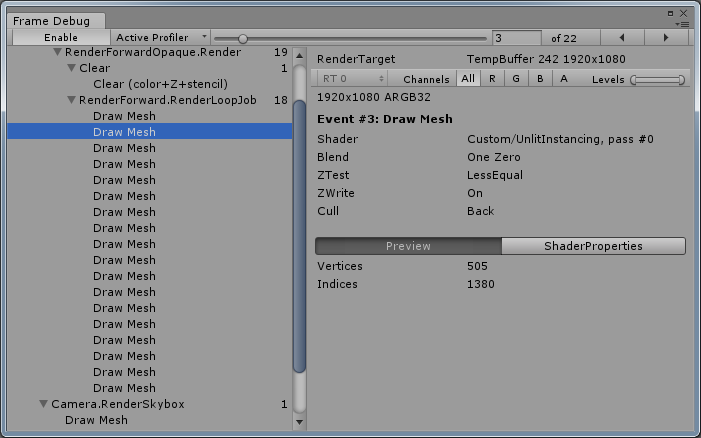
方案B:
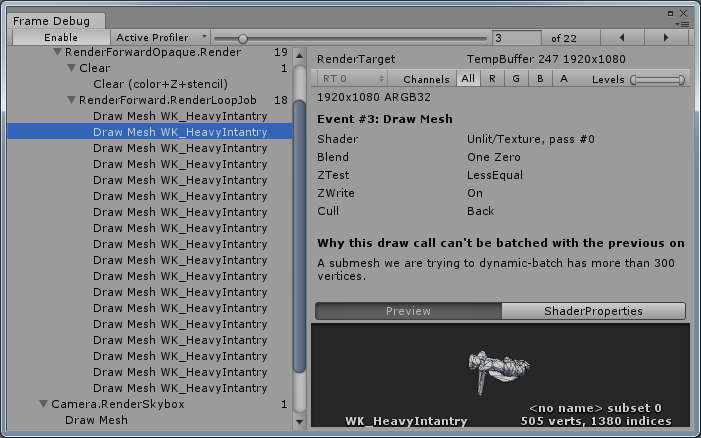
方案C:
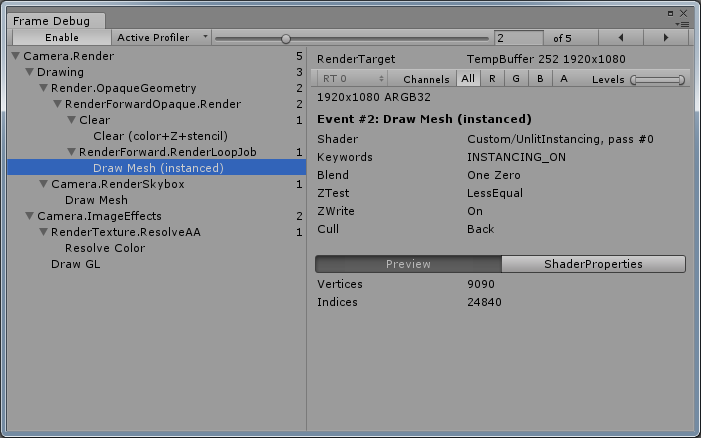
方案D:
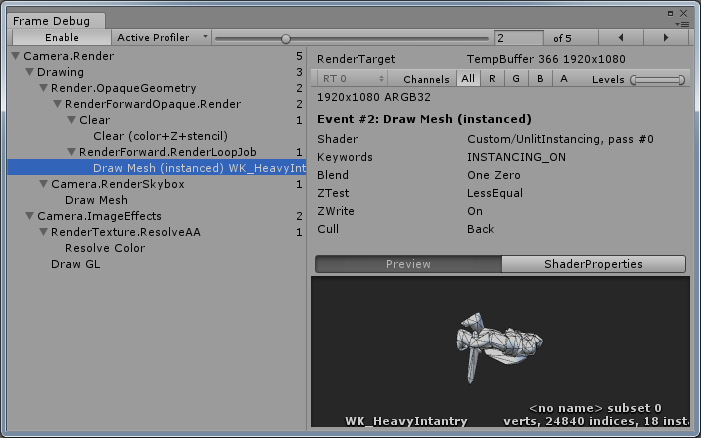
可以看到,方案B中因为超出300顶点这一限制所以无法合批,但是修改材质之后(方案D),支持GPU Instancing,不再受此限制的约束。
包含以上四个方案的项目工程都放在github。
一些弯路
除了前边的一些方案之外,还曾经走过一些弯路。在使用基于共享网格的迭代一方案时,发现会因为顶点数量超出限制而导致网格和材质都相同的多次绘制无法合批。就想到使用Mesh.Combine来合并网格,初始化时合并一次并在每帧更新顶点和变换矩阵,或者每帧合并。
使用这种方案,确实可以合批降低DC,但是大大增加了CPU的计算负荷,相比之下整体性能降低,在移动平台上FPS不升反降。于是抛弃了此方案。
其它思路
另外有一些思路,做了一些简单尝试,但是未落实成具体方案:
实时三渲二
使用另外的相机将小兵模型绘制到RenderTexture,然后将此RT作为纹理,在场景中使用12个2D的Sprite来显示。
目前项目中使用的是正交相机且固定相机位置,此方案是可行的。但是后期需求变化可能会替换为透视相机且相机允许转动,每个小兵呈现出的2D图像不同,这一方案将失效。
抛开无法满足未来需求这一点,还有其它的一些因素需要考虑,这种绘制方式可能增加额外的性能开销,如多了一个相机和RT,各个Sprite的空间位置关系、绘制层级控制,小兵与HUD的绘制层级控制等。
几何着色器
在shader中增加几何着色器(Geometry shader),以控制将一个模型的顶点(三角形)绘制出更多份。由于项目最终是部署到Android和iOS平台,所以很快放弃了这一思路。
如果将来会有PC或者主机平台的项目,或许可以尝试。将原来的坐标转换(MVP矩阵变换)的工作从顶点着色器中移出,放入几何着色器。并且几何着色器中将输入的顶点(三角形)绘制多份,最终送达片段着色器一并绘制。由于对于Unity及图形学的研究尚浅,不知这种方案是否可以实现,如果真的可以实现,也不了解这种方法是否会带来更大的性能开销,待后续有时间再研究研究这个。
Animation Instancing
最后一个方案是Animation Instancing,这种方法是在网上看到的(链接),由于与项目中的需求有些差异,并且时间关系也没有去做更多的探索。这种方案可以针对更高要求的SMR合批绘制,不限制各个SMR必须有相同的动作。预先生成动画保存到纹理中,然后运行时读取纹理来播放动画,大幅降低了CPU的负载(提升了少量GPU的负荷和内存占用),整体的渲染性能大大提升。但是目前无法支持动画状态切换,不过作者表示很快会支持这一功能。
REFERENCE
https://docs.unity3d.com/ScriptReference/SkinnedMeshRenderer.html
https://docs.unity3d.com/ScriptReference/Graphics.html
https://blogs.unity3d.com/cn/2018/04/16/animation-instancing-instancing-for-skinnedmeshrenderer/